
In this post, we will see what SOLID means and how to implement it using C#.
SOLID is a mnemonic acronym for five designers principles that help us to write software more understandable, easier to maintain, flexible and easier to extend.
The five principles are:
Single responsibility principle
Open/closed principle
Liskov substitution principle
Interface segregation principle
Dependency inversion principle
SINGLE RESPONSABILITY PRINCIPLE:
It says that a module/class should be only responsible for one task.
We define a class called Employee:
public class Employee
{
public int Id { get; set; }
public string Name { get; set; }
public string Username { get; set; }
public int EmployeeDetailsId { get; set; }
}
Now, we define a Interface used to manage Employee and then, we will create a class to implement the interface’s methods:
public interface IEmployeeCore
{
void CreateEmployee(Employee em);
void UpdateEmployee(Employee em);
void GetAllEmployee(Employee em);
void GenerateEmployeeReport();
}
public class EmployeeCore: IEmployeeCore
{
public void CreateEmployee(Employee em)
{
// To DO
}
public void UpdateEmployee(Employee em)
{
// To DO
}
public void GetAllEmployee(Employee em)
{
// To DO
}
public void GenerateEmployeeReport()
{
// To DO
}
}
In according to the Single responsibility principle, we should move the GenerateEmployeeReport in another class because it doesn’t manage the Employee class.
If we apply the Single responsibility principle, we should have a code like that:
// Definition of IReport Interface
// where we define all methods for creating reports
public interface IReport
{
void GenerateEmployeeReport();
void GenerateEmployerReport();
void GenerateCompanyReport();
}
public class Report: IReport
{
public void GenerateEmployeeReport()
{
// To DO
}
public void GenerateEmployerReport()
{
// To DO
}
public void GenerateCompanyReport()
{
// To DO
}
}
public interface IEmployeeCore
{
void CreateEmployee(Employee em);
void UpdateEmployee(Employee em);
void GetAllEmployee(Employee em);
// Definition of a method used to generate a Report
void GenerateReport();
}
public class EmployeeCore: IEmployeeCore
{
private IReport objReport;
public EmployeeCore(IReport inputReport)
{
objReport = inpuReport;
}
public void CreateEmployee(Employee em)
{
// To DO
}
public void UpdateEmployee(Employee em)
{
// To DO
}
public void GetAllEmployee(Employee em)
{
// To DO
}
public void GenerateReport()
{
// In this method, we will call the method
// created into Report class
objReport.GenerateEmployeeReport();
}
}
OPEN/CLOSED PRINCIPLE:
It says that software entities (classes, modules, functions, etc.) should be open for extensions but closed for modification.
For this reason, we should write code that doesn’t have to change every time the requirements change.
We define a class called Command1 and a class called ExecuteCommand:
public class Command1
{
public decimal Value { get; set; }
}
public class ExecuteCommand
{
public decimal Run(Command1 objCommand)
{
return objCommand.Value() * objCommand.Value();
}
}
Now, if we want to add a new class called Command2, we need to change the class ExecuteCommand too, in order to use Command2:
public class Command2
{
public decimal Value1 { get; set; }
public decimal Value2 { get; set; }
}
public class ExecuteCommand
{
public decimal Run(object objCommand)
{
if(objCommand is Command1)
{
var comm = (Command1)objCommand;
return comm.Value * comm.Value;
}
else
{
var comm = (Command2)objCommand;
return (comm.Value1 * comm.Value2)/33;
}
}
}
It works, but if we want to add another class, it means change ExecuteCommand again.
In according the Open/closed principle, we should’t change ExecuteCommand every time we add a Command.
If we apply the Open/closed principle, we should have a code like that:
public abstract class Command
{
public abstract decimal Exec();
}
public class Command1:Command
{
public decimal Value { get; set; }
public ovveride decimal Exec()
{
return Value * Value;
}
}
public class Command2:Command
{
public decimal Value1 { get; set; }
public decimal Value2 { get; set; }
public ovveride decimal Exec()
{
return (Value1 * Value2)/33;
}
}
public class Command3:Command
{
public decimal Value1 { get; set; }
public decimal Value2 { get; set; }
public decimal Value3 { get; set; }
public ovveride decimal Exec()
{
return (Value1 + Value2)/Value3;
}
}
public class ExecuteCommand
{
public decimal Run(Command objCommand)
{
return objCommand.Exec();
}
}
LISKOV SUBSTITUTION PRINCIPLE:
It says that if a module is using a Base class then, the reference to that Base class can be replaced with a Derived class, without affecting the functionality of the module.
We define one class called Command1 and then another class called Command2, that inherit Command1:
public class Command1
{
public virtual string RunCommand()
{
return "RunCommand";
}
public virtual string StopCommand()
{
return "StopCommand";
}
}
public class Command2 : Command1
{
public override string RunCommand()
{
return "RunCommand1";
}
public override string StopCommand()
{
throw new Exception("not implemented");
}
}
Now, if we try to use Command2 instead of Command1, we don’t receive a compile error, but when we run the application, we will receive a runtime error:
class Program
{
static void Main(string[] args)
{
Command objCommand = new Command1();
Console.WriteLine(objCommand.RunCommand());
Console.WriteLine(objCommand.StopCommand());
objCommand = new Command2();
Console.WriteLine(objCommand.RunCommand());
Console.WriteLine(objCommand.StopCommand());
}
}
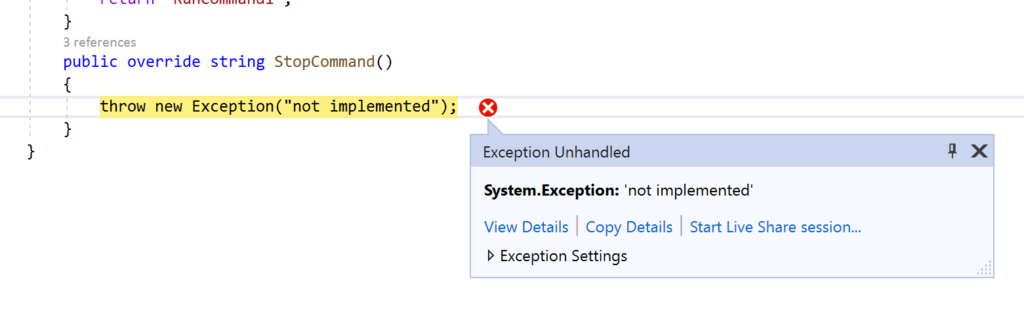
In according the Liskov substitution principle, we should change Command1, in order to avoid a runtime error.
If we apply the Liskov substitution principle, we should have a code like that:
public interface CommandRun
{
public string RunCommand();
}
public interface CommandStop
{
public string RunCommand();
}
public class Command1:CommandRun,CommandStop
{
public string RunCommand()
{
return "RunCommand";
}
public string StopCommand()
{
return "StopCommand";
}
}
public class Command2 : CommandRun
{
public string RunCommand()
{
return "RunCommand1";
}
}
Now, if we try to use Command2 instead of Command1, we will receive a compile error:
class Program
{
static void Main(string[] args)
{
Command1 objCommand = new Command1();
Console.WriteLine(objCommand.RunCommand());
Console.WriteLine(objCommand.StopCommand());
objCommand = new Command2(); // ERROR
Console.WriteLine(objCommand.RunCommand());
Console.WriteLine(objCommand.StopCommand());
}
}
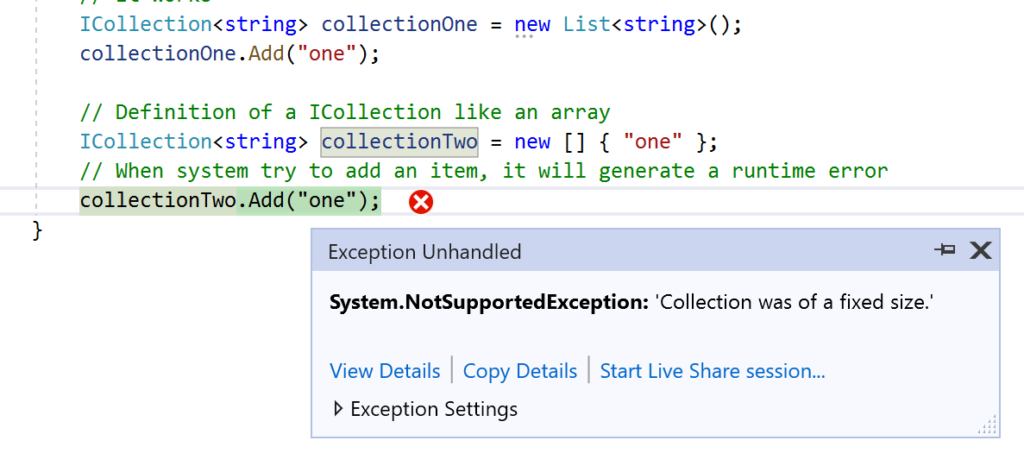
One last thing: this is an example of a Liskov substitution principle violation in the .NET framework design:
static void Main(string[] args)
{
// Definition of a ICollection like a list of string
// It works
ICollection<string> collectionOne = new List<string>();
collectionOne.Add("one");
// Definition of a ICollection like an array
ICollection<string> collectionTwo = new [] { "one" };
// When system try to add an item, it will generate a runtime error
collectionTwo.Add("one");
}
INTERFACE SEGREGATION PRINCIPLE:
It says that clients should not be forced to implement interfaces they don’t use.
Instead of one fat interface, many small interfaces are preferred based on groups of methods, each one serving one submodule.
We define an Interface called ICommand and we create two classes Exec1 and Exec2, that inherit ICommand:
public interface ICommand
{
decimal CommandOne(decimal val1, decimal val2);
decimal CommandTwo(decimal val1, decimal val2);
decimal CommandThree(decimal val1, decimal val2);
decimal CommandFour(decimal val1, decimal val2);
}
public class Exec1:ICommand
{
public decimal CommandOne(decimal val1, decimal val2)
{
return (val1*val2)/12;
}
public decimal CommandTwo(decimal val1, decimal val2)
{
return (val1/val2)*3;
}
public decimal CommandThree(decimal val1, decimal val2)
{
return (val1+val2)/(val1 - val2);
}
public decimal CommandFour(decimal val1, decimal val2)
{
throw new Exception(“Not allowed”);
}
}
public class Exec2:ICommand
{
public decimal CommandOne(decimal val1, decimal val2)
{
return (val1*val2)/12;
}
public decimal CommandTwo(decimal val1, decimal val2)
{
return (val1/val2)*3;
}
public decimal CommandThree(decimal val1, decimal val2)
{
rthrow new Exception(“Not allowed”);
}
public decimal CommandFour(decimal val1, decimal val2)
{
return (val1-val2)/0.2;
}
}
It works, but we can see that in both classes there are some methods didn’t implement.
In according the Interface segregation principle, we should break down ICommand in more Interfaces.
If we apply the Interface segregation principle, we should have a code like that:
public interface ICommandOne
{
decimal CommandOne(decimal val1, decimal val2);
decimal CommandTwo(decimal val1, decimal val2);
}
public interface ICommandTwo
{
decimal CommandThree(decimal val1, decimal val2);
}
public interface ICommandThree
{
decimal CommandFour(decimal val1, decimal val2);
}
public class Exec1: ICommandOne, ICommandTwo
{
public decimal CommandOne(decimal val1, decimal val2)
{
return (val1*val2)/12;
}
public decimal CommandTwo(decimal val1, decimal val2)
{
return (val1/val2)*3;
}
public decimal CommandThree(decimal val1, decimal val2)
{
return (val1+val2)/(val1 - val2);
}
}
public class Exec2: ICommandOne, ICommandThree
{
public decimal CommandOne(decimal val1, decimal val2)
{
return (val1*val2)/12;
}
public decimal CommandTwo(decimal val1, decimal val2)
{
return (val1/val2)*3;
}
public decimal CommandFour(decimal val1, decimal val2)
{
return (val1-val2)/0.2;
}
}
DEPENDENCY INVERSION PRINCIPLE:
It says that a high level modules should not depend on low-level modules but, should depend on abstraction.
We define a class Log that we will use in another class called Command:
public class Log
{
void Write(string error)
{
File.WriteAllText(@"C:\Error.txt", error);
}
}
public class Command
{
Log logger = new Log();
public void Exec(DataCommand inputCommand)
{
try
{
inputCommand.run();
}
catch (Exception error)
{
logger.Write(error.ToString());
}
}
}
It works, but in according the Dependency inversion principle, we shouldn’t create Log instance from within Command.
If we apply the Dependency inversion principle, we should have a code like that:
public interface ILog
{
void Write(string error);
}
public class Log: ILog
{
void Write(string error)
{
File.WriteAllText(@"C:\Error.txt", error);
}
}
public class Command
{
private ILog _log;
public Command(ILog inputLog)
{
_log = inputLog;
}
public void Exec(DataCommand inputCommand)
{
try
{
inputCommand.run();
}
catch (Exception error)
{
_log.Write(error.ToString());
}
}
}
Nice article.
With SINGLE RESPONSABILITY PRINCIPLE, I understand that we should separate the object as much as possible, I think separate very small it is not good because we will difficult to management source code
In reality it will be easier, because it is very easy change and testing small piece of code instead of a big piece of code that could manage many functionalities.